Building HIPAA-Compliant AI in Healthcare: What Actually Works in 2026

Healthcare has never been short on innovation. What it has struggled with is scaling innovation inside one of the most regulated data environments in the world.
That tension is becoming increasingly visible as artificial intelligence moves deeper into healthcare operations. From clinical documentation and patient engagement to revenue cycle management, AI is no longer being treated as an emerging technology. It is becoming part of the infrastructure that healthcare organisations rely on every day, not as a pilot, but as operational infrastructure. Which raises the question most organisations haven't fully answered yet: can it handle protected health information at this scale without getting the compliance layer badly wrong?
The ones getting it right aren't the ones with the most powerful models. They're the ones who treated compliance as architecture, not an afterthought.
The industry data makes the urgency clear:
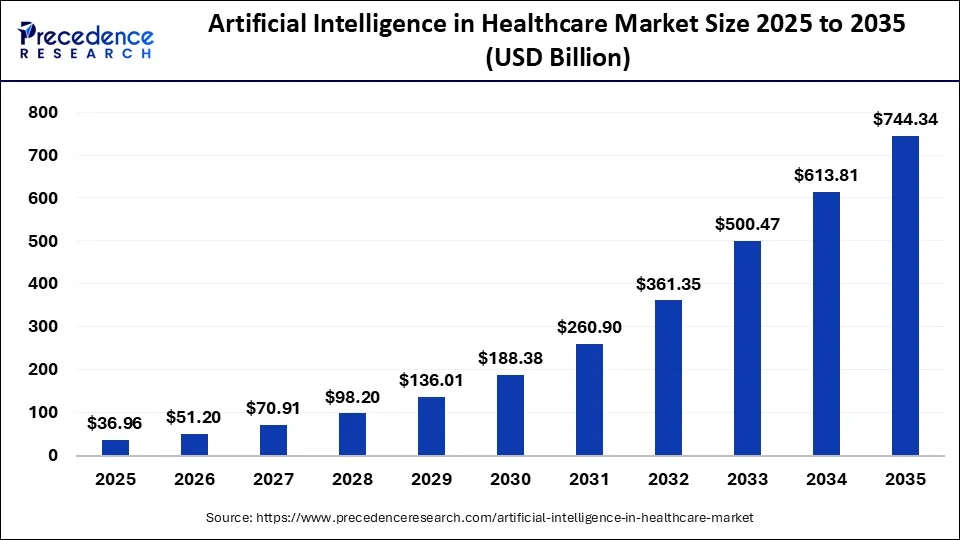
- Healthcare AI is a $51.2 billion market in 2026, projected to reach $744 billion by 2035. And Compliance failures are the single biggest risk at this scale.
- McKinsey estimates $1 trillion in unrealised improvement potential inside U.S. healthcare that AI can unlock.
- 63% of U.S. physicians now use AI in clinical practice, up from 47% nine months earlier. Most of that AI touches patient data without a real compliance architecture behind it.
- In 2024, 725 healthcare breaches exposed 275 million records, 82% of the U.S. population's health data, in a single year.
- Vector embeddings of patient data are PHI under HIPAA. Most teams building RAG systems find this from OCR, not from their engineering lead.
- A BAA makes your vendor contractually responsible. It does not fix broken architecture. That part is still yours.
Source: Precedence Research
The Rules Changed, and Most Teams Are Still Playing by the Old Ones.
The regulatory environment for healthcare AI in 2026 is not what it was in 2022. Most teams moved fast on deployment and assumed compliance would follow. It didn't, and in some cases, the rules shifted while they were still building. What makes this particularly costly is that none of these changes was subtle. They were published, debated, and enforced. Yet, most teams just weren't paying attention.
In December 2024, HHS OCR published the first proposed update to the HIPAA Security Rule since 2013. The core change: controls organisations had long argued their way around —MFA, audit logging, network segmentation—would become hard requirements with no room for interpretation. The rule isn't finalised yet, but OCR isn't waiting for finalisation to tighten enforcement.
OCR also launched its first HIPAA audit cycle since 2016, targeting 50 covered entities and business associates, with a focus on cybersecurity and ransomware exposure. If your AI systems lack a documented security architecture, this is how you find out.
March 2024 brought another shift that most AI teams completely overlooked. ONC's HTI-1 Final Rule now requires EHR developers to show their work on any AI clinical decision support tool, where the training data came from, how the algorithm assesses risk, and how it performs across different patient populations. If your AI sits inside a certified EHR, that obligation is already yours, and most teams found out after the fact.
4 Things That Actually Determine If Your Healthcare AI Is Compliant
Most compliance programmes focus on the wrong layer. Here is what actually matters.
1) Where PHI Actually Goes in Your Stack
Most teams treat a signed BAA as the end of the compliance conversation. It isn't even close.
A BAA tells you who is contractually responsible when something goes wrong. It says nothing about whether your patient data is actually protected; that depends entirely on how your system is built. Under 45 CFR §164.504(e), every vendor handling PHI on your behalf is a Business Associate, your AI platform, your cloud provider and every tool in the chain. Having contracts with all of them doesn't mean any of them are handling that data correctly.
Here's where the major platforms stand:
2) What Happens When Your Model Meets Patient Data
Training an AI on patient records without de-identifying them first creates a problem most teams don't see coming. PHI doesn't disappear once training is done; it can persist in the model weights. Researchers have shown that LLMs reproduce training data verbatim under specific prompting conditions. A model built on your EHR is, in effect, carrying patient information in a form your standard access controls were never designed to address.
Two approaches actually work:
Federated learning solves the problem at the source. Instead of moving patient data to a central training environment, you send the model to the data. Each hospital trains locally and sends back only model updates; the underlying records never move.
NVIDIA FLARE is the open-source framework behind real deployments of this, including an initiative run across 71 international healthcare sites whose results were published in Nature Medicine. The federated model outperformed the centrally trained ones. Massachusetts General Hospital and the American College of Radiology both run on this framework.
Differential privacy goes a step further by adding calibrated noise to model updates before they leave each site, making it impossible to reconstruct individual patient records from the shared data. Google's DP library and Meta's Opacus for PyTorch are both production-ready. The tradeoff is a small hit to model accuracy; most healthcare applications find that acceptable.
De-identification sounds straightforward until you realise there are two legally distinct methods under 45 CFR §164.514, and most teams can't tell you which one they're actually using: Safe Harbor requires stripping 18 specific identifiers, names, SSNs, phone numbers, IP addresses, dates, geographic data, and more. ZIP codes are the one that trips people up most: you can only keep the first three digits if the area covers a population of at least 20,000. Miss any single identifier and the data is still PHI, regardless of how clean everything else looks.
Expert Determination takes a different approach altogether. A qualified statistician assesses the actual risk of someone being re-identified from the data and signs off on the conclusion that the risk is genuinely small. It gives you more flexibility in what you can keep, but it requires a documented methodology and someone prepared to put their name behind the conclusion. Amazon Comprehend Medical and the Google Cloud Healthcare API both handle Safe Harbour automation well in practice, including stripping identifiers burned directly into DICOM radiology images, which catches more teams off guard than you'd expect.
3) Controlling Who and What Accesses Your AI Systems
For years, hospital IT operated on a simple assumption: if traffic is inside the network, it can be trusted. AI breaks that assumption completely, not because it introduces new threats, but because it creates new access points that were never part of the original security model.
That is exactly what Zero Trust was built for. Under NIST SP 800-207, nothing gets access simply because it is on the right network. Every request to an AI system gets verified fresh — who is asking, what device they are on, what they need access to. A clinician on hospital Wi-Fi still has to prove it is them, on a clean device, with a legitimate reason to be there.
Micro-segmentation makes this practical at scale. Each component sits in its own isolated segment — AI model containers, FHIR connectors, EHR integrations. If a radiology AI tool is compromised, it stays contained. It cannot reach billing infrastructure, pharmacy records, or anything beyond its own boundary. VMware NSX and Illumio are the most commonly used solutions in production healthcare environments for implementing this. It sounds like a large undertaking. At this point, it is simply the standard.
4) The Audit Trail HIPAA Actually Requires
Most teams set up logging. Fewer set up the kind of logging that would survive an OCR investigation.
Under 45 CFR §164.312(b), every system that contains or uses patient data must record and examine activity, and for AI, that scope is wider than most engineering teams account for:
- Every prompt containing or referencing PHI — who sent it, when, what data was included
- Every model output containing PHI — what was generated and what sources it drew from
- Every authentication event, data access, and model version change
- Access logs for vector databases holding patient embeddings
AWS CloudTrail, Azure Monitor, and Google Cloud Audit Logs handle the API-level capture automatically. That part is usually fine. Where most teams fall short is the application layer — logging which specific patient records were included in an AI query, not just that a query happened.
Those logs need to be retained for six years under 45 CFR §164.316, stored separately from application data, append-only so nothing can be quietly removed, and encrypted at rest. But the part most organisations miss is the last requirement: they have to be actively reviewed. A server full of logs nobody reads is not a compliant audit programme. It is just storage. OCR knows the difference, and their first request in any investigation is to see the audit trail.
What's Actually Running in Production Right Now
The Doximity 2026 report found 75% of physicians currently using AI say it has already reduced administrative burden. 65% estimate it could reallocate one to five additional hours per week toward direct patient care. The demand is real, and it's why production deployments are accelerating.
Microsoft Dragon Copilot — ambient AI clinical documentation built on Azure OpenAI, is live across thousands of clinicians at Intermountain Health, Mercy Health, and Yale New Haven, among others. Intermountain reported a 27% reduction in note time per appointment with 2,500+ active clinician users. Mercy's nurses report roughly 2 hours saved per 12-hour shift on charting—vendor-reported figures, but consistent across independent health systems.
Epic covers 325 million patient records and has ambient AI documentation accessible to every health system on its platform. If you've seen a doctor recently, there's a strong chance this technology was already in that room. What these deployments have in common is that compliance wasn't added at the end. It was designed from the start.
Aidoc has 17 FDA-cleared algorithms running in more than 1,600 hospitals. Radiologists at Cedars-Sinai saw ICU stays drop by 23%. At the University of Chicago, the time to detect a brain bleed fell by 35%. Those figures did not come from a marketing deck — they were published in Radiology: Artificial Intelligence and Brain Sciences. In a field where vendors routinely oversell outcomes, that distinction matters.
Three Things Nobody Mentions Until the Audit
Your vector database may be storing PHI without you knowing. Most teams think de-identification solves the data problem. It does — until patient records are stored in a vector database. Those numerical embeddings don't lose their PHI status just because the format changed. They carry the same encryption requirements, access controls, and six-year retention obligations as the source records. And when a patient requests deletion, most vector databases lack the ability to remove a specific record without complete provenance mapping built in from the start. Build that mapping before you need it.
RAG systems pull more patient data than necessary. The minimum necessary standard is one of HIPAA's most overlooked requirements, and RAG systems consistently violate it. An AI scheduling a follow-up appointment has no business pulling a complete patient chart, but that is exactly what happens when retrieval is not scoped at the query level. Application-layer controls do not fix this. The retrieval itself has to be limited to what the task actually needs.
Shadow AI is already inside your organisation. IBM's 2025 Cost of a Data Breach Report found 63% of organisations that experienced AI-related security incidents had no governance policies in place. The Doximity 2026 report found that only 8% of physicians say their organisation's AI policies are clear enough to follow. One clinician using the wrong ChatGPT tier with a patient record is a violation, and it is happening at scale in organisations that genuinely believe they are compliant.
Compliance Is The Foundation
HIPAA-compliant AI in healthcare isn't a question of whether to build it. It's a question of how to build it right. The organisations that succeed will be the ones that treat compliance, security and data governance as the starting point, not the final step.
There is also a strong economic case. Healthcare organisations that build the compliance layer properly return $3.20 for every dollar invested within 14 months, according to a Microsoft-IDC study. But those returns only materialise if the compliance architecture actually holds.
This isn't about making healthcare AI harder to build. It's about making sure it actually delivers what it promises: better patient outcomes, stronger institutional trust, and systems that hold up when they are needed most.
In healthcare, building the most powerful model is not the goal. Building one that clinicians trust, patients trust, and regulators accept, and none of that happens without compliance built in from the beginning.
Frequently Asked Questions
What makes an AI system HIPAA-compliant in 2026?
The BAA with your cloud vendor is just the starting point. Every vendor that actually touches patient data needs one, and that list gets longer once you trace where PHI really moves in your stack. Access controls and audit logging need to satisfy the HIPAA Security Rule, not just clear your internal review. Training data has to be de-identified under 45 CFR §164.514 before it reaches a model, miss one of the 18 required identifiers, and it's still PHI, no matter how clean the rest looks. Six years of logs retained.
One thing teams find out late: since March 2024, any AI clinical decision support running within a certified EHR must show its work, training data sources, risk basis, and how it performs across different patient populations. ONC's HTI-1 Final Rule made that a legal requirement, not a future roadmap item. If your product lives inside an EHR and this isn't handled, it's already out of compliance.
Does Azure OpenAI have a HIPAA BAA?
Yes, and it's one of the cleaner setups in the industry. Microsoft bundles the BAA directly into standard Azure licensing through the Data Protection Addendum, so if you're already an Azure customer, you're already covered, no separate contract, no negotiation. Azure OpenAI Service falls under that coverage when you're running inside a HIPAA-configured account.
Can you use ChatGPT or Claude with patient data?
Not the consumer versions ever. Standard ChatGPT and Claude.ai don't carry HIPAA BAAs, which means using them with patient data isn't a grey area; it's a violation. The enterprise tiers are a different story: both OpenAI Enterprise and Anthropic's Claude Enterprise offer BAAs for healthcare customers. The tier matters enormously here, so confirm it before any PHI gets near an AI system.
Are vector embeddings considered PHI under HIPAA?
Yes, and this catches a surprising number of teams off guard. When you generate embeddings from patient records for a RAG system or semantic search, those vectors don't shed their PHI status just because the format changed. They need the same encryption, the same access controls and the same six-year retention as the source data. The other problem: most vector databases don't offer BAAs, so check your vendor before storing patient embeddings, and build deletion-safe provenance mapping from day one, not after a patient submits a records request.



